 dbt
dbt Airflow
Airflow Openflow
Openflow Git / CI
Git / CI PySpark
PySpark Snowpark
Snowpark Databricks
Databricks Dataproc
Dataproc Fabric
Fabric EMR
EMR BigQuery
BigQuery Redshift
RedshiftAnalyze and Insights
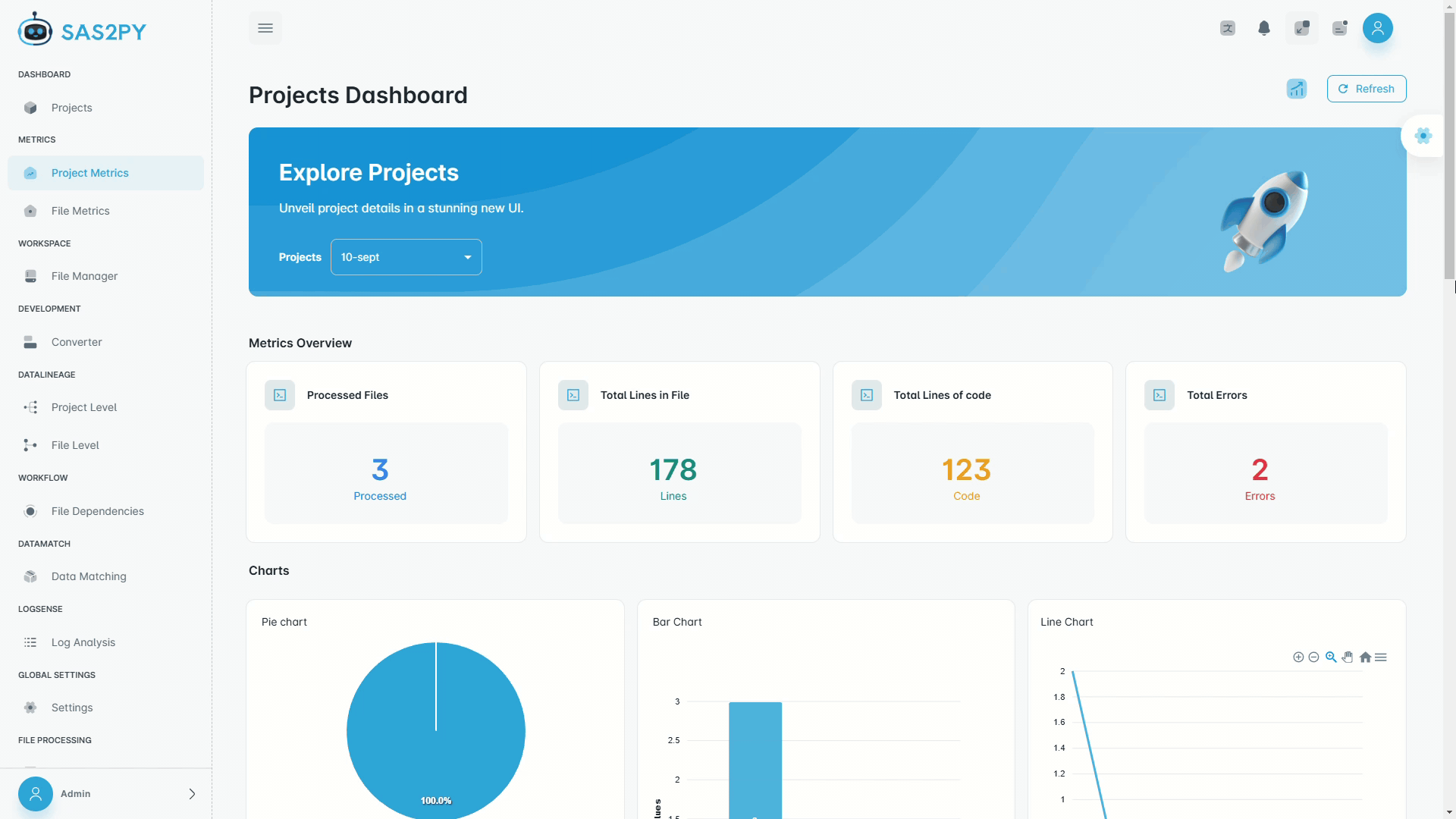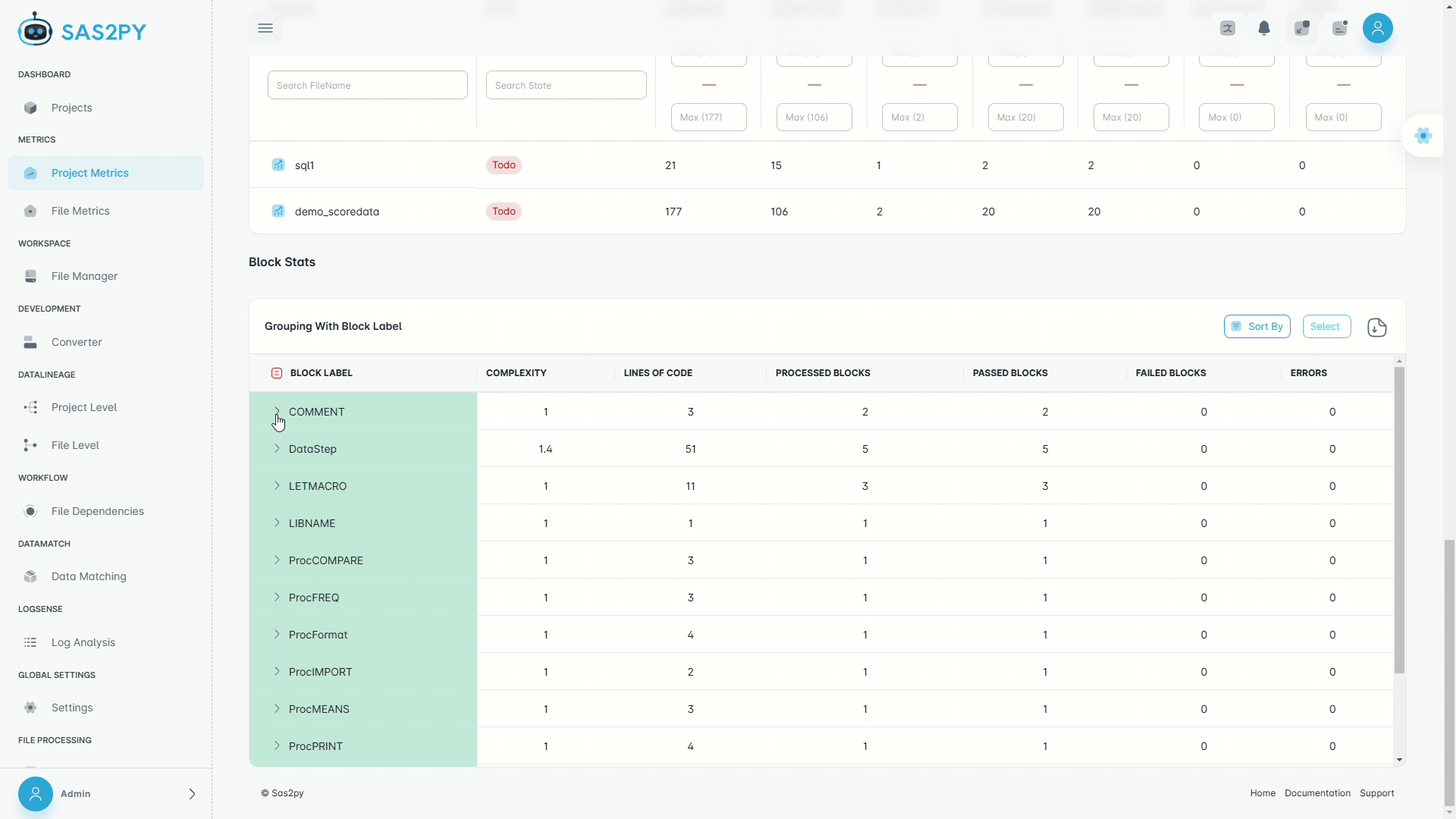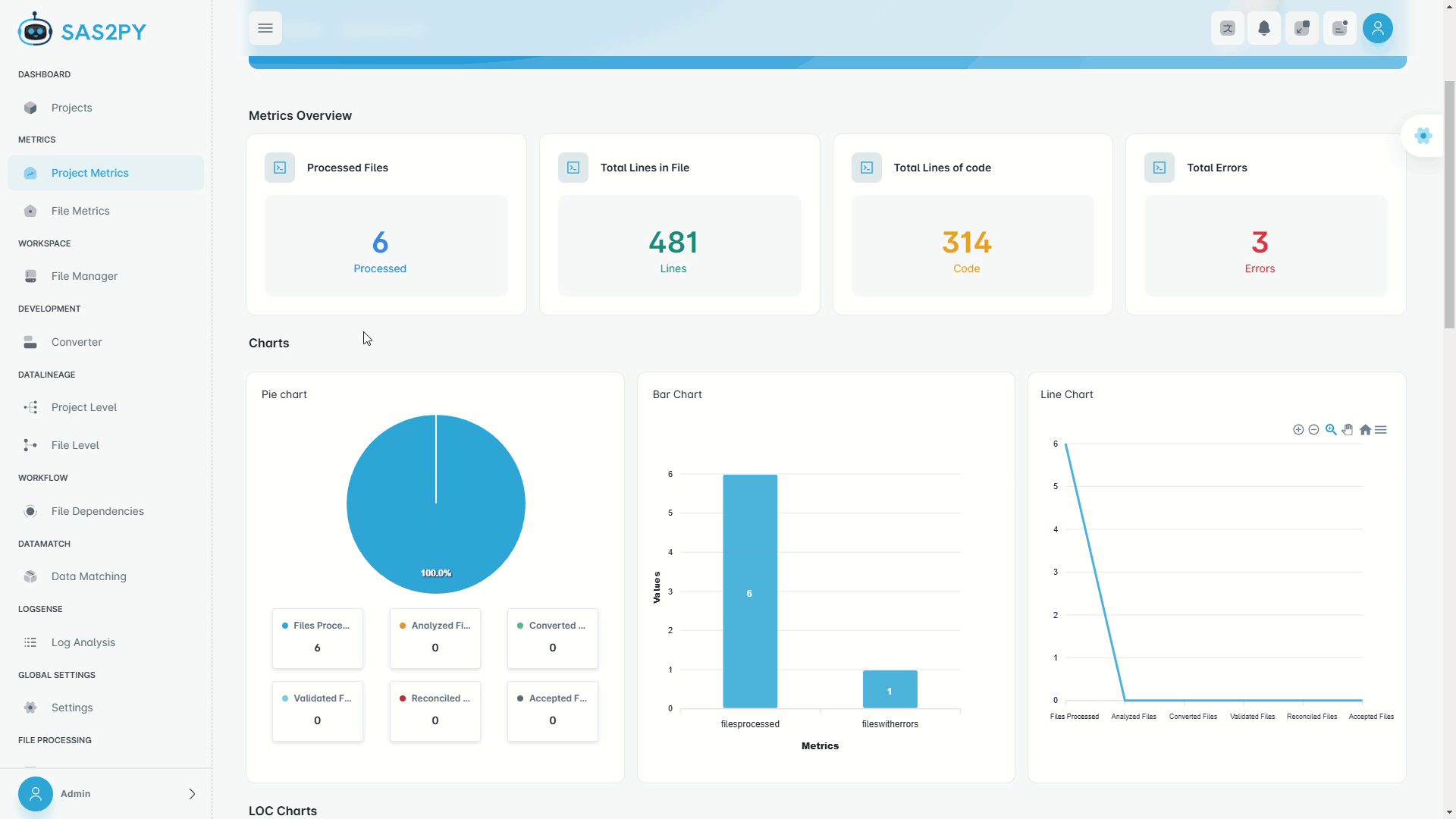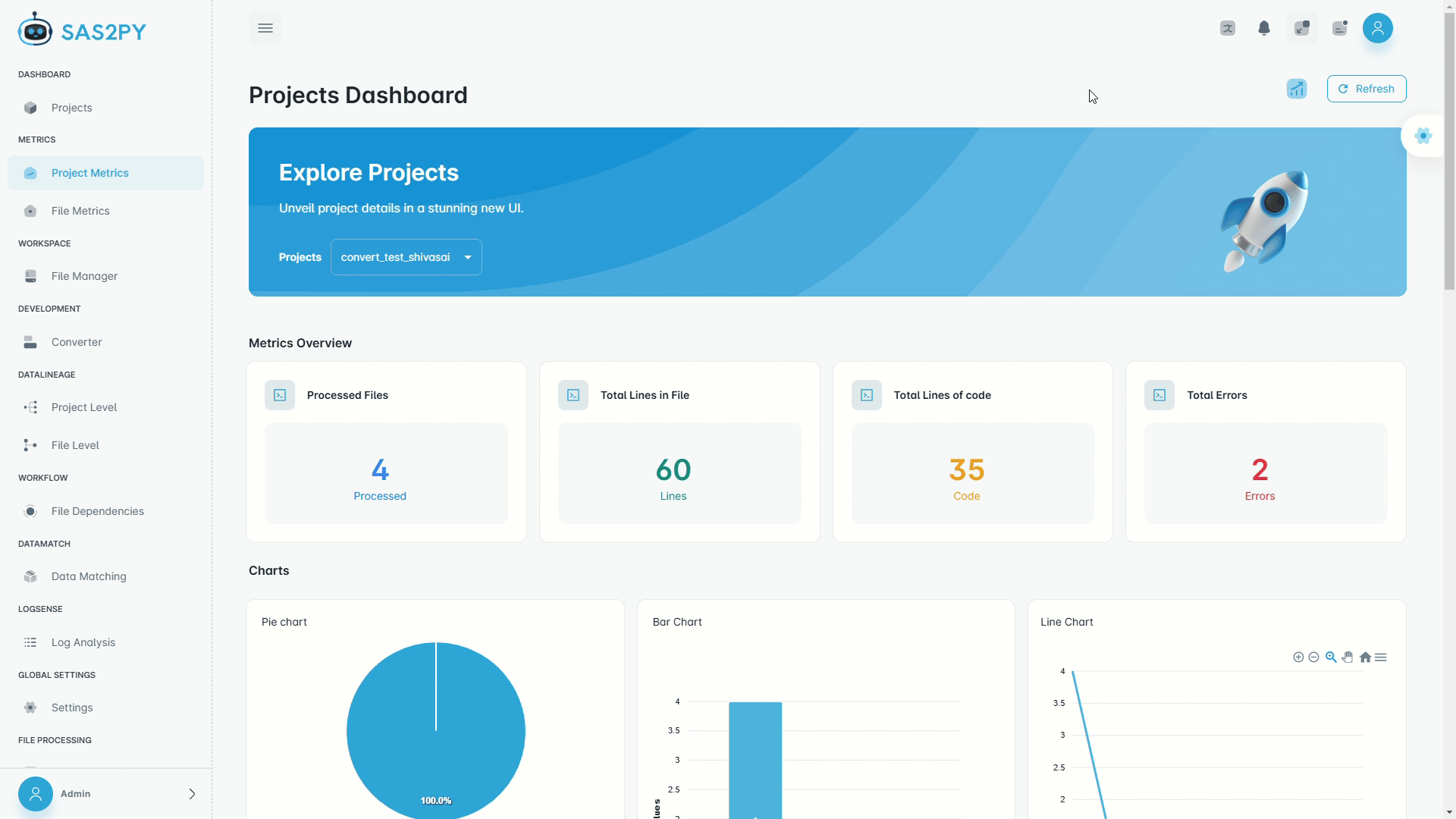
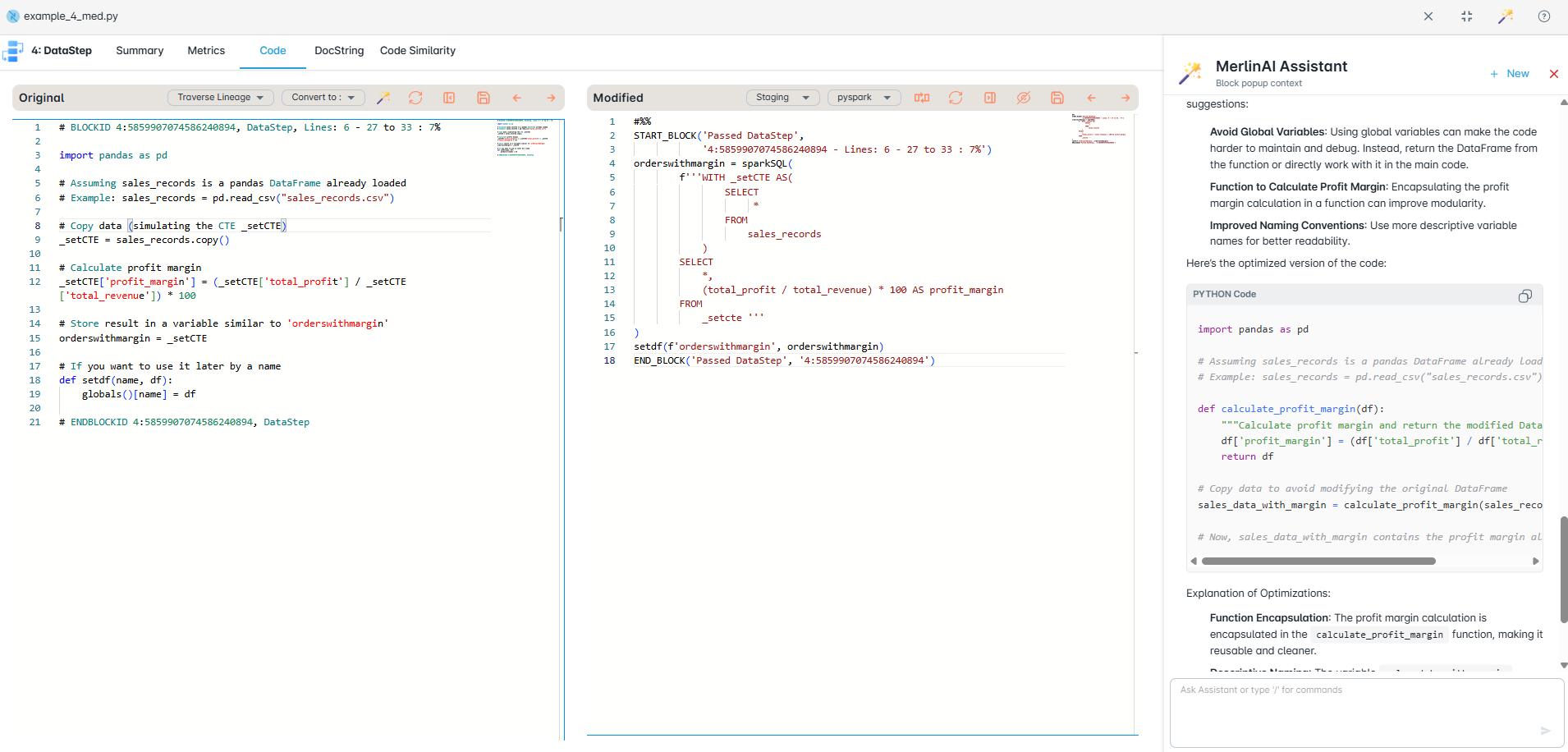
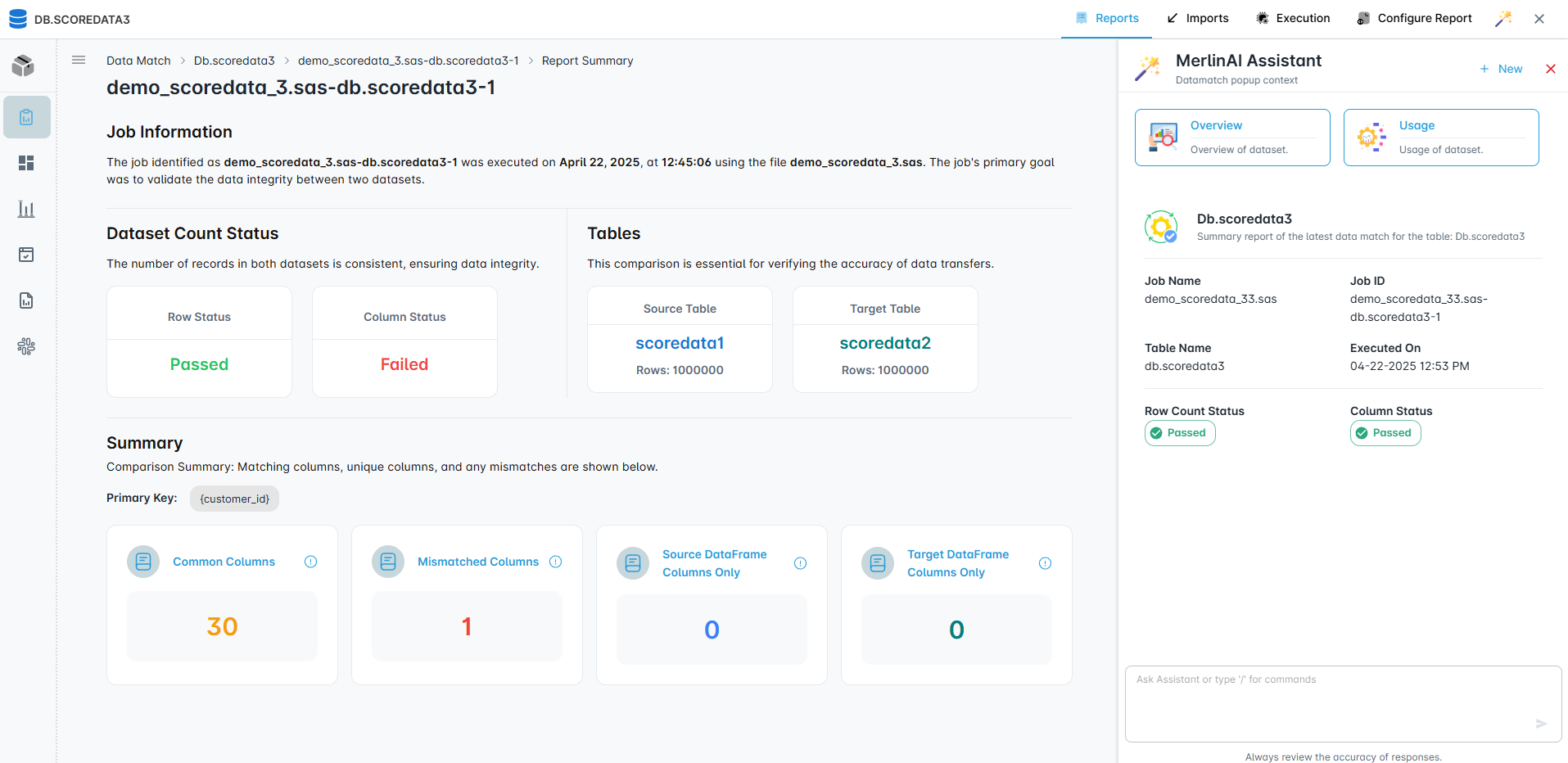
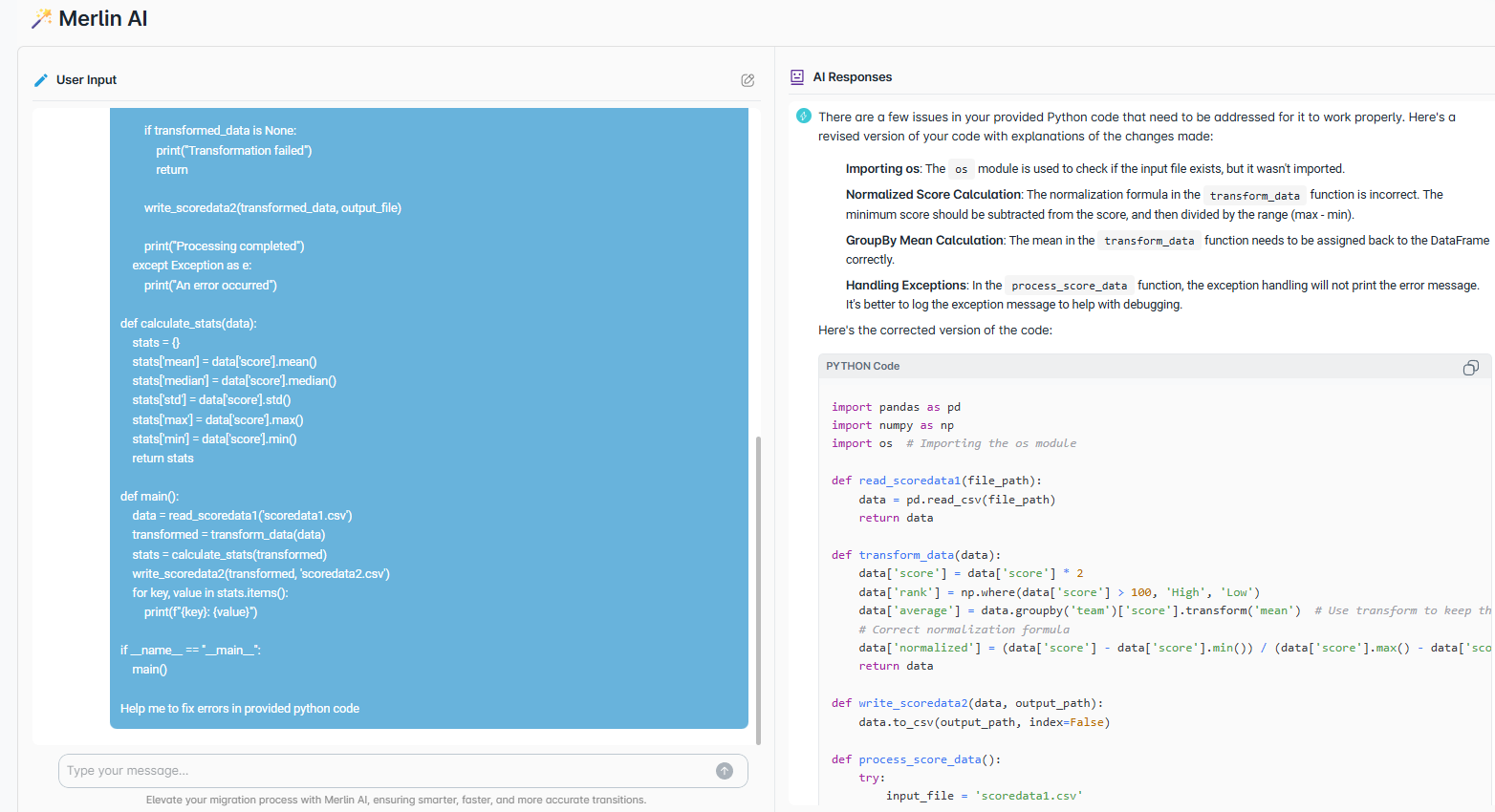
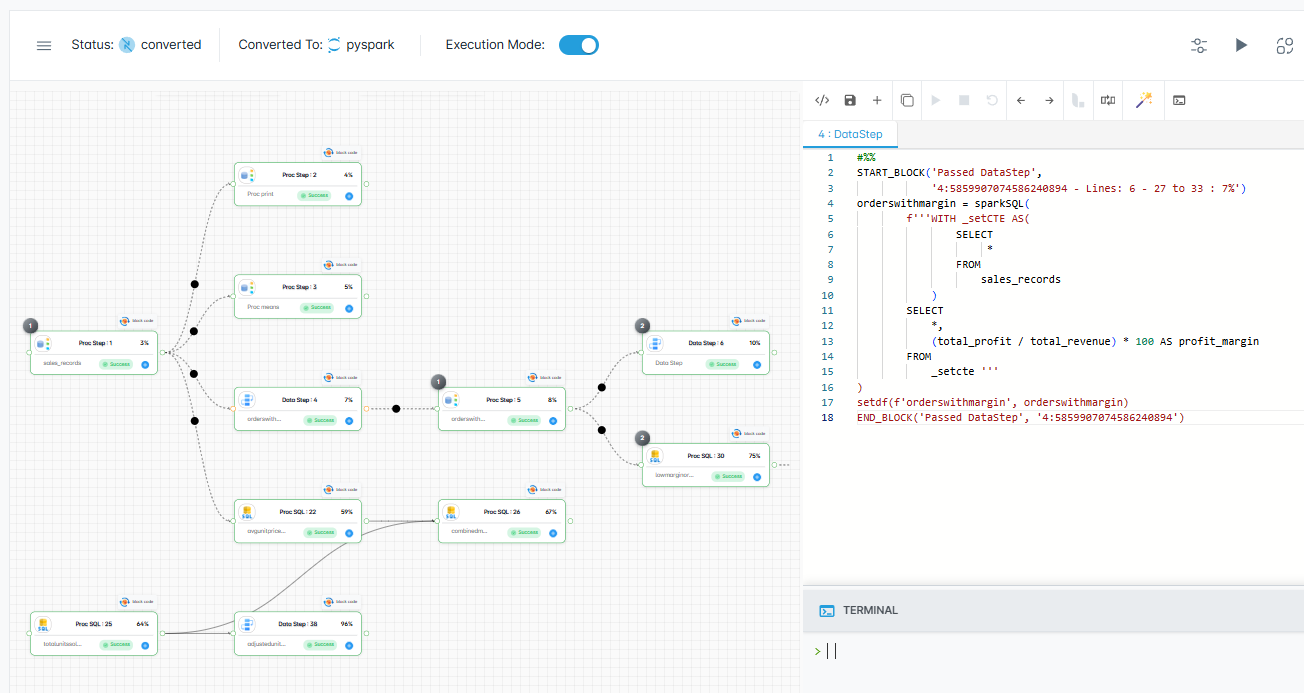
- Automatic code assessment for rationalization and migration planning
- Comprehensive dependency mapping with data and file lineage
- Development of required frameworks and standards
- Code complexity analysis, block labels, and LoC assessment
- Rationalize and standardize current ETL